二、Docker镜像管理#
1. 查看、查找镜像#
使用 docker images 命令可以列出本地系统上所有的 Docker 镜像,包括镜像的仓库名称、标签、镜像 ID、创建时间和大小等信息。
docker images
输出示例:
REPOSITORY TAG IMAGE ID CREATED SIZE
nginx latest 7f7b05e59d6a 2 weeks ago 142MB
ubuntu 20.04 8d5c9eec5b6a 3 weeks ago 64.2MB
docker search [OPTIONS] 镜像名字
参数:
--limit nu #只输出查到的前nu条记录
docker search redis --limit 3 # 放在镜像名称前面后面均可
字段解析:
NAME:镜像名称
DISCRIPTION:镜像说明
STARTS:点赞数
OFFICAL:是否是官方认可的
AUTOMATED:是否自动构建
2. 拉取镜像(Pull)#
从 Docker Hub 或其他镜像仓库拉取镜像到本地。使用 docker pull 命令来下载镜像。默认从 Docker Hub 拉取镜像。
docker pull <image_name>:<tag>
例如,拉取最新的 Ubuntu 镜像:
docker pull ubuntu:20.04
如果没有指定标签,默认拉取 latest 标签的镜像。
镜像难以拉取,则需要在 /etc/daocker/daemon.json 配置加速器
3. 构建镜像(Build)#
使用 docker build 命令根据 Dockerfile 构建镜像。Dockerfile 是一个包含镜像构建步骤的文本文件,它定义了如何从基础镜像创建新的镜像。
Dockerfile有多个重要指令,后面会说明
构建镜像的命令:
docker build -t <image_name>:<tag> <path_to_dockerfile>
例如,在当前目录构建一个名为 my-app 的镜像:
docker build -t my-app:latest .
4. 镜像标签(Tagging)#
镜像标签用于标识镜像的不同版本。每个镜像默认有一个标签 latest,但你可以使用 docker tag 命令为镜像打上新的标签。
docker tag <image_id> <new_image_name>:<new_tag>
例如,为 my-app 镜像打上版本标签:
docker tag my-app:latest my-app:v1.0
5. 推送镜像(Push)#
将本地镜像上传到 Docker 仓库(如 Docker Hub 或私有仓库)。首先需要登录 Docker 仓库:
docker login
然后使用 docker push 将镜像推送到远程仓库:
docker push <image_name>:<tag>
例如,推送 my-app:latest 镜像到 Docker Hub:
docker push my-app:latest
6. 删除镜像(Remove)#
如果不再需要某个镜像,可以使用 docker rmi 命令删除它。删除镜像时,Docker 会检查该镜像是否被容器使用,若被使用则无法删除。
docker rmi <image_name>:<tag>
例如,删除 my-app:latest 镜像:
docker rmi my-app:latest
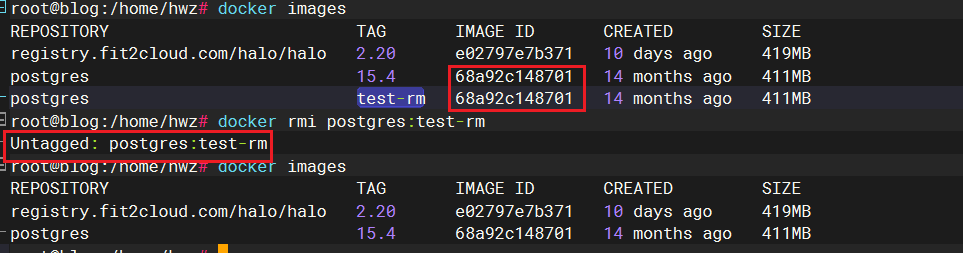
如果镜像被多个标签引用,可以一次性删除多个标签的镜像:
docker rmi <image_id>
如果没有删除所有的镜像,怎只会解除当前镜像的tag,而不会删除源镜像
#删全部
docker rmi -f $(docker images -qa)
7. 清理未使用的镜像#
Docker 会产生很多没有被使用的镜像,这些镜像会占用磁盘空间。使用 docker system prune 或 docker image prune 命令清理未使用的镜像、容器、网络和构建缓存。
docker system prune
8. 查看镜像历史#
使用 docker history 命令可以查看镜像的构建历史。它列出了镜像的每一层及其创建的命令。
docker history <image_name>:<tag>
例如,查看 ubuntu:20.04 镜像的历史:
docker history ubuntu:20.04
9. 镜像仓库#
Docker 镜像通常存储在仓库中。Docker Hub 是默认的公共镜像仓库,用户也可以使用私有仓库存储镜像。常见的 Docker 镜像仓库有:
- Docker Hub:Docker 官方公共镜像仓库
- 私有镜像仓库:通过 Docker Registry 创建自己的私有镜像仓库,适合企业内部使用
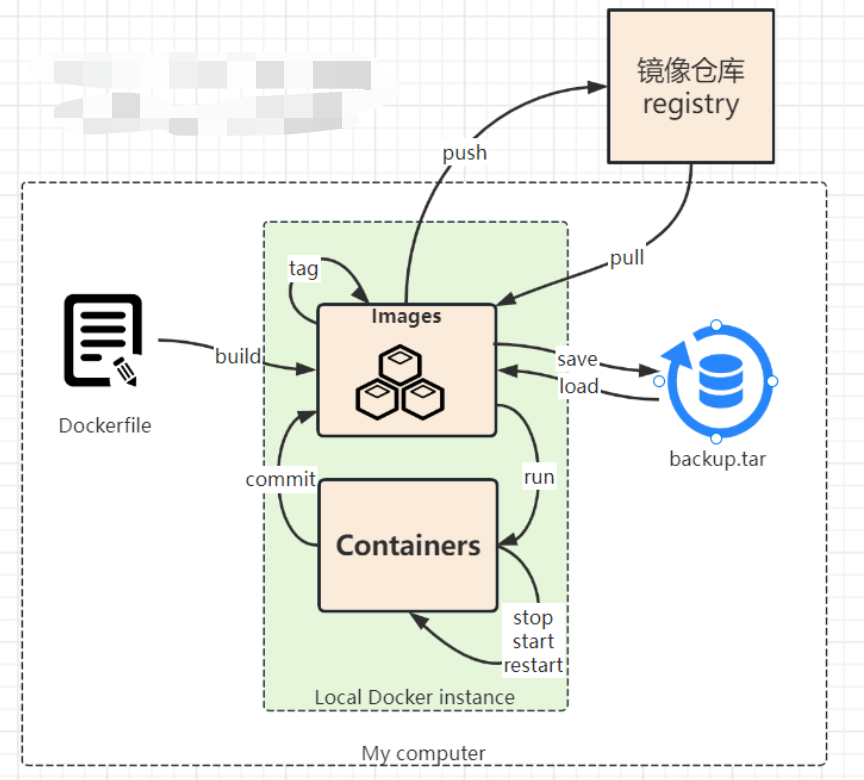
10. 导入及导出镜像#
导出镜像为tar包#
# 直接导出为tar包
docker save -o image.tar image:tag
docker save image_id -o /home/mysql.tar
docker save image_id > /home/mysql.tar
#导出多个镜像为1个tar包
docker save -o <output-file.tar> <image1>:<tag1> <image2>:<tag2> ...
导入tar包为镜像#
docker load -i mysql.tar
[root@localhost ~]# docker load -i /usr/local/rancher-v2.3.5.tar
43c67172d1d1: Loading layer [==================================================>] 65.57MB/65.57MB
21ec61b65b20: Loading layer [==============================......
c22c9a5a8211: Loading layer [==================================================>] 3.072kB/3.072kB
Loaded image: rancher/rancher:v2.3.5
11. 备份镜像#
docker save $(docker images | sed 1d | awk
‘{print $1}’) > centos-all.tar
常见镜像命令总结#
| 命令 | 作用 | ||||
|---|---|---|---|---|---|
docker images | 列出所有本地镜像 | ||||
docker pull <image_name> | 从仓库拉取镜像 | ||||
docker build -t <name>:<tag> | 根据 Dockerfile 构建镜像 | ||||
docker tag <image> <new_tag> | 为镜像添加标签 | ||||
docker push <image> | 推送镜像到远程仓库 | ||||
docker rmi <image> | 删除本地镜像 | ||||
docker system prune | 清理无用的镜像、容器、网络等 | ||||
| docker save -o | 保存镜像到本地 | ||||
| docker load -i | 导入本地镜像 |
三、Docker容器管理#
1. 容器概述#
1.1 什么是容器#
- 通过Image创建(copy)
- 在Image layer之上建立一个container layer(可读写)
- 类比面向对象:类和实例
- Image负责app的存储和分发,Container负责运行app
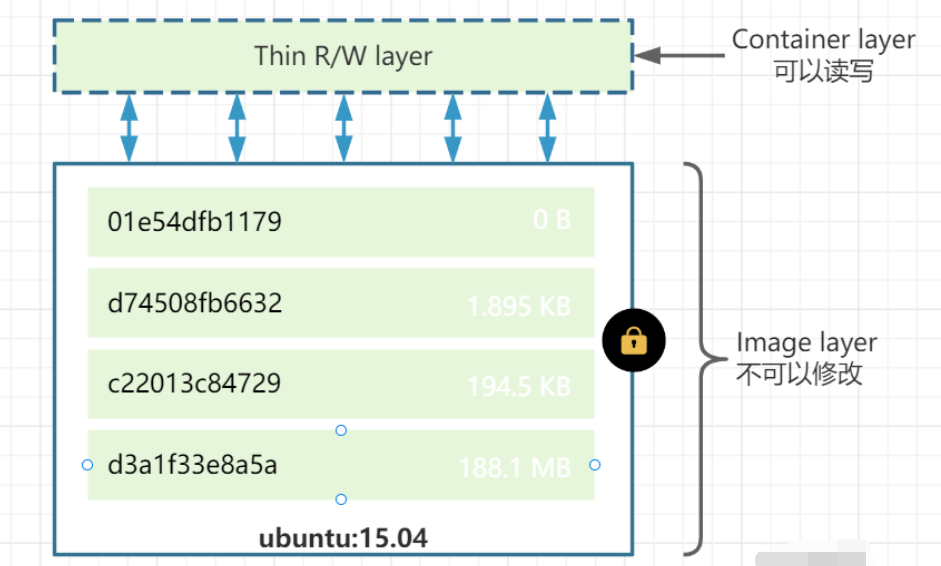
1.2 容器与镜像的关系#
- 镜像:镜像是只读文件,提供运行程序完整的软硬件资源。
- 容器:容器是镜像的实例,由docker负责创建,容器之间彼此隔离
2. 容器的使用#
2.1 启动容器(Run)#
使用 docker run 命令可以从镜像启动一个新的容器,并运行指定的命令。该命令也可用来设置容器的环境变量、挂载卷、设置端口映射等。
docker run [OPTIONS] <image_name> [COMMAND]
例如,使用 nginx 镜像启动一个容器,并将本地 80 端口映射到容器的 80 端口:
docker run -d -p 80:80 --name my-nginx nginx
eg:
以ubuntu为例,启动后要交互先声明交互模式,其次交互得需要一个终端,因此参数为-it
docker run -it ubuntu /bin/bash #伪终端登陆
docker run -it --name=myubuntu ubuntu /bin/bash #指定名称
docker run -d redis:6.0.8 #后台运行、守护式容器
注意
上面的docker run -d ubuntu 执行后,使用docker ps -a进行查看,会发现容器已经退出
很重要的要说明的一点: Docker容器后台运行,就必须有一个前台进程.
常用选项:
-d:后台运行容器(即脱离终端)-p:端口映射--name:给容器指定一个名字-e:设置环境变量
| 选项 | 描述 |
|---|---|
-i, --interactive | 交互式模式,保持容器标准输入打开 |
-t, --tty | 分配一个伪终端,用于连接到容器的终端 |
-d, --detach | 在后台运行容器,不阻塞终端 |
-e, --env | 设置环境变量,格式:-e <key>=<value> |
-p, --publish list | 发布容器端口到主机,格式:-p <host_port>:<container_port> |
-P, --publish-all | 发布容器所有 EXPOSE 的端口到宿主机随机端口 |
--name string | 指定容器的名称 |
-h, --hostname | 设置容器的主机名 |
--ip string | 指定容器的 IP 地址,仅限于自定义网络 |
--network | 连接容器到指定的网络 |
-v, --volume list | 将宿主机目录或卷挂载到容器中,格式:-v <host_path>:<container_path> |
--mount mount | 使用新方式将文件系统或存储挂载到容器,格式:--mount type=bind,source=<source>,target=<target> |
--restart string | 设置容器退出时的重启策略,默认值为 no,可选值:[always |
-m, --memory | 限制容器的最大内存使用量 |
--memory-swap | 容器允许使用的交换空间大小(包括内存和 swap) |
--memory-swappiness=<0-100> | 设置容器使用 swap 的倾向性,取值范围 [0-100],默认为 -1 |
--oom-kill-disable | 禁用 OOM Killer,当容器内存耗尽时不会被杀掉 |
--cpus | 设置容器可以使用的 CPU 数量 |
--cpuset-cpus | 限制容器使用特定的 CPU 核心,如 --cpuset-cpus="0-3,0,1" |
--cpu-shares | 设置容器的 CPU 权重,用于 CPU 资源的分配(相对权重) |
2.2 查看容器列表#
使用 docker ps 命令查看当前正在运行的容器。如果要查看所有容器(包括已停止的),可以使用 docker ps -a。
docker ps # 查看正在运行的容器
docker ps -a # 查看所有容器,包括已停止的
参数:
-a :列出当前所有正在运行的容器+历史上运行过的
-l :显示最近创建的容器。
-n nu:显示最近nu个创建的容器。
-q :静默模式,只显示容器编号。
输出示例:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
1a2b3c4d5e6f nginx "/docker-entrypoint.…" 2 minutes ago Up 2 minutes 0.0.0.0:80->80/tcp my-nginx
2.3 进入、退出容器#
进入容器#
如果想要进入容器的内部进行调试或操作,可以使用 docker exec 命令:
docker exec -it <container_id_or_name> /bin/bash
例如,进入名为 my-nginx 的容器:
docker exec -it my-nginx /bin/bash
退出容器#
① exit
run进去容器,exit退出,容器停止
② ctrl+p+q
run进去容器,ctrl+p+q退出,容器不停止
容器内外的文件复制#
docker cp 容器ID:容器内路径 目的主机路径 #从容器内拷贝文件到主机上
eg:
#以ubuntu为例,我们在/tmp目录下通过touch a.txt创建a文本,将其复制到本机download目录下
docker cp 958443b97285:/tmp/a.txt /download
#有一个名为 my_container 的容器,并且希望将主机上的文件 /tmp/myfile.txt 复制到容器内的 /app 目录:
docker cp /tmp/myfile.txt my_container:/app/
2.4 停止容器#
要停止一个运行中的容器,使用 docker stop 命令。可以根据容器的 ID 或名称停止容器。
docker stop <container_id_or_name>
例如,停止名为 my-nginx 的容器:
docker stop my-nginx
2.5 重启容器#
要重启一个容器,可以使用 docker restart 命令,这对于更新配置或者重启容器应用非常有用。
docker restart <container_id_or_name>
例如,重启名为 my-nginx 的容器:
docker restart my-nginx
2.6 删除容器#
删除已停止的容器,可以使用 docker rm 命令。需要注意的是,删除容器时,该容器内的数据会丢失,除非使用了卷(Volumes)来持久化数据。
docker rm <container_id_or_name>
例如,删除名为 my-nginx 的容器:
docker rm my-nginx
如果容器在运行,且你希望同时停止并删除它,可以使用 -f 强制删除容器:
docker rm -f <container_id_or_name>
2.7 查看容器日志#
要查看容器的日志输出,可以使用 docker logs 命令。这对于调试应用程序或排查错误非常有用。
docker logs <container_id_or_name>
例如,查看名为 my-nginx 容器的日志:
docker logs my-nginx
如果要实时查看日志,可以使用 -f 选项:
docker logs -f <container_id_or_name>
2.8 查看容器的详细情况#
要查看容器的资源使用情况(如 CPU、内存等),可以使用 docker stats 命令。它会显示所有容器的资源使用信息,或者你可以指定某个容器查看其资源使用情况。
docker stats # 查看所有容器的资源使用情况
docker stats <container_id_or_name> # 查看指定容器的资源使用情况
参数:
--all , -a :显示所有的容器,包括未运行的。
--format :指定返回值的模板文件。
--no-stream :展示当前状态就直接退出了,不再实时更新。
--no-trunc :不截断输出。
eg:
docker stats
docker stats mynginx # 容器名
docker stats af7928654200 # 容器ID

字段解析
CONTAINER ID 与 NAME: 容器 ID 与名称。
CPU % 与 MEM %: 容器使用的 CPU 和内存的百分比。
MEM USAGE / LIMIT: 容器正在使用的总内存,以及允许使用的内存总量。
NET I/O: 容器通过其网络接口发送和接收的数据量。
BLOCK I/O: 容器从主机上的块设备读取和写入的数据量。
PIDs: 容器创建的进程或线程数。
# docker stats统计结果只能是当前宿主机的全部容器,数据资料是实时的,没有地方存储、没有健康指标过线预警等功能,如果现象要实现监控数据持久化并以图表等形式展现,可以使用CIG,即CAdvisor监控收集+InfluxDB存储数据+Granfana展示图表
要查看容器里的进程使用情况,使用docker top 查看容器内的进程
docker top 容器ID #查看容器内运行的进程
2.9 管理容器网络#
Docker 容器之间可以通过 Docker 网络进行通信。你可以创建自定义网络、连接容器到网络,或者查看网络配置。
创建网络:
docker network create <network_name>连接容器到指定网络:
docker network connect <network_name> <container_id_or_name>查看容器网络:
docker network ls删除网络
docker network rm XXX网络名字查看网络相关信息
docker network inspect XXX网络名字
2.10 容器与卷(Volumes)#
使用卷#
为了持久化容器中的数据,可以使用 Docker 卷(Volumes)。卷存储在 Docker 守护进程外部,容器停止或删除时,卷中的数据不会丢失。可以将容器中的目录挂载到卷上。
创建一个卷:
docker volume create <volume_name>使用卷启动容器:
docker run -d -v <volume_name>:<container_path> <image_name>
例如,使用 my-volume 卷启动一个容器:
docker run -d -v my-volume:/data nginx
docker run -it --privileged=true -v /宿主机绝对路径目录:/容器内目录:[OPTION] 镜像名
参数:
rw 可读可写(read + write)
ro 容器实例内部被限制,只能读取不能写,仅读(read only)
eg:
docker run -it --privileged=true --name=u1 -v /tmp/docker_data:/tmp/dockertest:ro ubuntu /bin/bash
docker run -it --privileged=true --name=u2 -v /tmp/docker_data:/tmp/dockertest ubuntu /bin/bash # 不写OPTION默认rw
挂载后可通过【docker inspect 容器ID】查看是否挂载成功
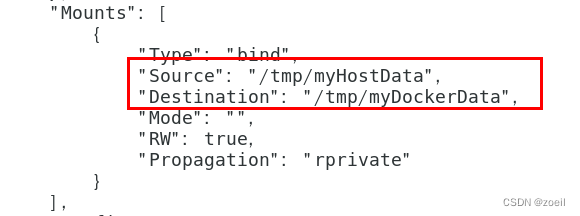
容器数据卷继承#
docker run -it --privileged=true --volumes-from 父类 --name u2 ubuntu
example:
# 新创建u3容器继承u2容器的数据卷挂载,此时u2就算stop也不影响u3
docker run -it --privileged=true --volumes-from u2 --name u3 ubuntu
2.11 容器的备份#
docker commit -m="提交的描述信息" -a="作者" 容器ID 要创建的目标镜像名:[标签名]
# 保存当前容器的状态
docker commit -a "author" -m "meassage" container_id
docker commit -a "author" -m "meassage" container_name
eg:
docker pull ubuntu
docker exec --it container_id /bin/bash
apt-get update
apt-get -y install vim
docker commit -m="ubuntu-add-vim" -a="zjy" a4b1b1cc54f0 atguigu/myubuntu:1.3
验证:
docker systemd df
docker images -a
仅会保存当前容器内的文件(包括cp进容器的文件),但不会保存挂载的volume或bind
2.12常见容器命令总结#
| 命令 | 描述 |
|---|---|
docker ps | 列出当前运行中的容器 |
docker inspect | 查看一个或多个容器的详细信息 |
docker exec | 在运行中的容器内执行命令 |
docker commit | 从容器创建一个新的镜像 |
docker cp | 拷贝文件或文件夹到容器中或从容器中拷贝到主机 |
docker logs | 获取容器的日志输出 |
docker port | 列出或指定容器端口映射 |
docker top | 显示容器中运行的进程 |
docker stats | 显示容器的实时资源使用统计信息 |
docker stop | 停止一个或多个运行中的容器 |
docker start | 启动一个或多个已停止的容器 |
docker restart | 重启一个或多个容器 |
docker rm | 删除一个或多个容器 |
docker prune | 移除所有已停止的容器,并释放占用的系统资源 |
四、Docker网络管理#
Docker网络架构的设计规范是CNM。CNM中规定了Docker网络的基础组成要素,完整内容见GitHub的docker/libnetwork库。
推荐通篇阅读该规范,不过其实抽象来讲,CNM定义了3个基本要素:沙盒(Sandbox)、终端(Endpoint)和网络(Network)。
沙盒是一个独立的网络栈。其中包括以太网接口、端口、路由表以及DNS配置。
终端就是虚拟网络接口。就像普通网络接口一样,终端主要职责是负责创建连接。在CNM中,终端负责将沙盒连接到网络。
网络是802.1d网桥(类似大家熟知的交换机)的软件实现。因此,网络就是需要交互的终端的集合,并且终端之间相互独立
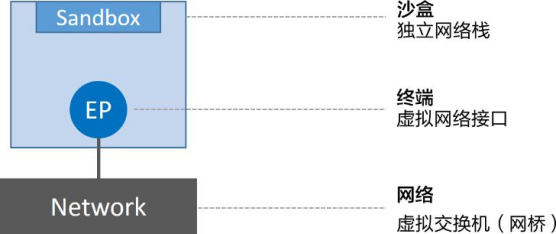
Docker环境中最小的调度单位就是容器,而CNM也恰如其名,负责为容器提供网络功能。
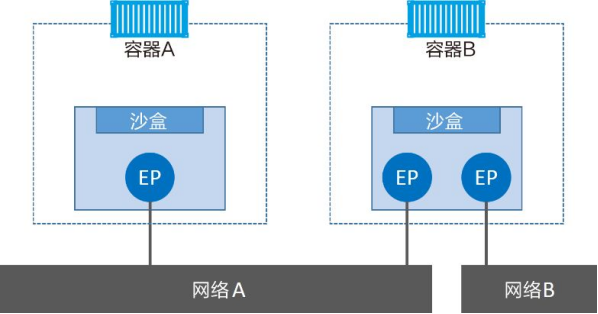
需要重点理解的是,终端与常见的网络适配器类似,这意味着终端只能接入某一个网络。因此,如果容器需要接入到多个网络,就需要多个终端。
网络部分代码都存在于daemon当中,Docker将该网络部分从daemon中拆分,并重构为一个叫作Libnetwork的外部类库。
Libnetwork实现了CNM中定义的全部3个组件。此外它还实现了本地服务发现(Service Discovery)、基于Ingress的容器负载均衡,以及网络控制层和管理层功能。
如果说Libnetwork实现了控制层和管理层功能,那么驱动就负责实现数据层。比如,网络连通性和隔离性是由驱动来处理的,驱动层实际创建网络对象也是如此,其关系如图所示。
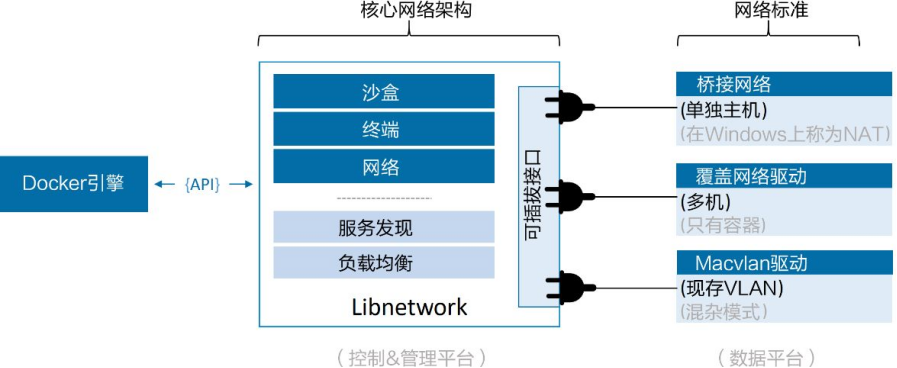
Docker封装了若干内置驱动,通常被称作原生驱动或者本地驱动。在Linux上包括Bridge 、Overlay 以及Macvlan
1. Bridge#
默认Bridge#
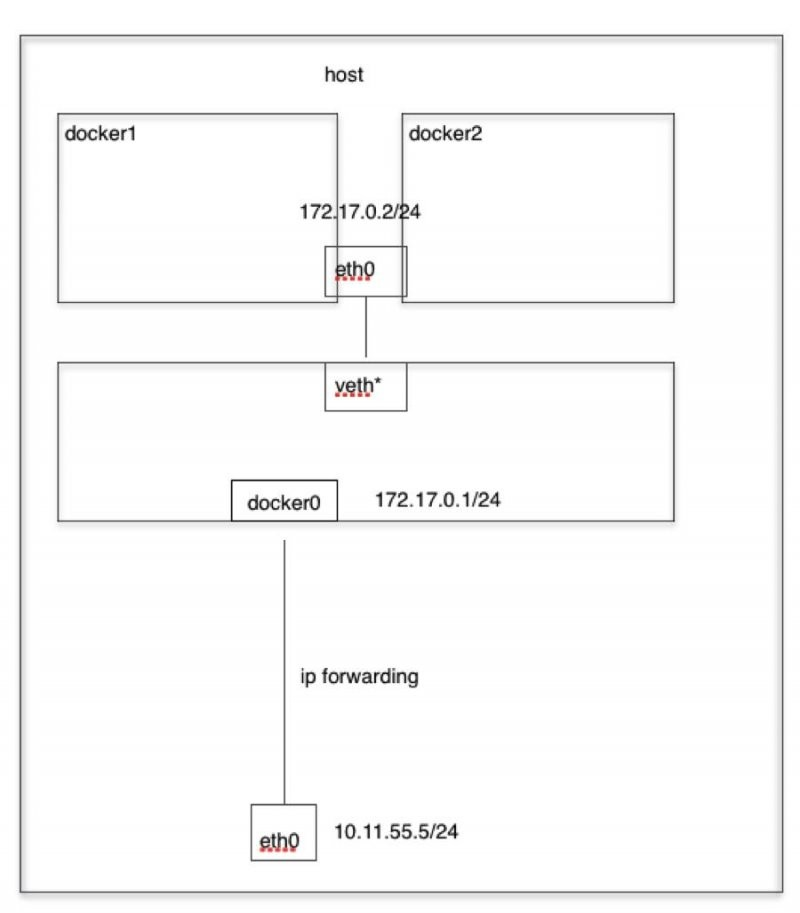
当 Docker 进程启动时,会在主机上创建一个名为 docker0 的虚拟网桥,此主机上启动的 Docker容器会连接到这个虚拟网桥上。虚拟网桥的工作方式和物理交换机类似,这样主机上的所有容器就通过交换机连在了一个二层网络中。
从 docker0 子网中分配一个 IP 给容器使用,并设置 docker0 的 IP 地址为容器的默认网关。在主机上创建一对虚拟网卡 veth pair 设备, Docker将 veth pair 设备的一端放在新创建的容器中,并命名为 eth0 (容器的网卡),另一端放在主机中,以 vethxxx 这样类似的名字命名,并将这个网络设备加入到 docker0 网桥中。可以通过brctl show命令查看
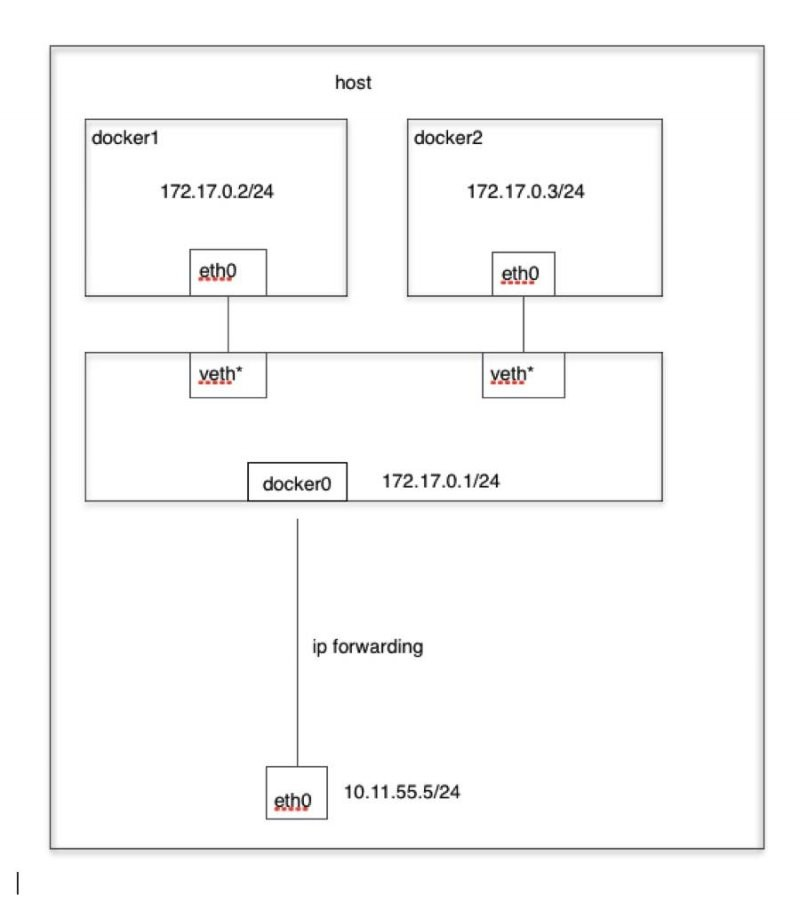
Docker默认“bridge”网络和Linux内核中的“docker0”网桥之间的关系如图
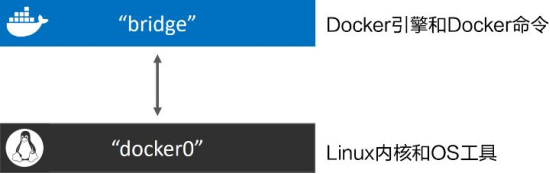
自定义Bridge#
使用docker network create 命令创建新的单机桥接网络,名为“localnet”。
docker network create -d bridge localnet
新的网络创建成功,并且会出现在docker network ls 命名的输出内容当中。如果读者使用Linux,那么在主机内核中还会创建一个新的Linux网桥
接下来通过使用Linux brctl 工具来查看系统中的Linux网桥。可能需要通过命令apt-get install bridge-utils 来安装brctl 二进制包,或者根据所使用的Linux发行版选择合适的命令。
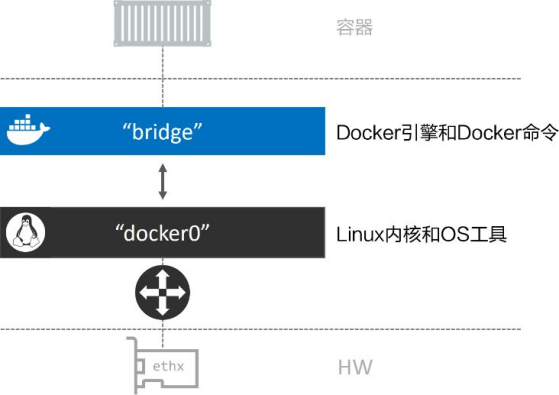
root@blog:/home/hwz# brctl show
bridge name bridge id STP enabled interfaces
br-5ac679535b8c 8000.0242858a17dd no veth4b19961 docker0 8000.0242ac80c4ca no vethf1e3e13
docker_gwbridge 8000.02425bb9fa03 no vethaad561c
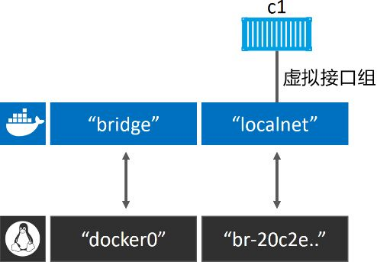
Linux上默认的Bridge网络是不支持通过Docker DNS*服务进行域名解析的。自定义桥接网络可以*!
(1)创建名为“c2”的容器,并接入“c1”所在的localnet 网络。
//Linux
$ docker container run -it --name c2 \
--network localnet \
alpine sh
(2)在“c2”容器中,通过“c1”容器名称执行ping 命令。
> ping c1
Pinging c1 [172.26.137.130] with 32 bytes of data:
Reply from 172.26.137.130: bytes=32 time=1ms TTL=128
Reply from 172.26.137.130: bytes=32 time=1ms TTL=128
Control-C
命令生效了!这是因为c2容器运行了一个本地DNS解析器,该解析器将请求转发到了Docker内部DNS服务器当中。Docker的 DNS服务器中记录了容器启动时通过–name 或者–net-alias 参数指定的名称与容器之间的映射关系。
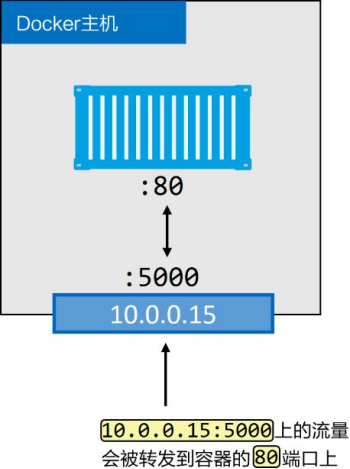
**桥接网络中的容器只能与位于相同网络中的容器进行通信。**但是,可以使用端口映射(Port Mapping)来绕开这个限制。
在端口映射时,Docker 并不关心宿主机和容器的 IP 地址是否在同一网段。Docker 负责处理从宿主机接收到的流量,并将其转发到正确的容器。端口映射的关键在于网络层面的路由和 NAT 转换,而不是 IP 地址的直接通信。
端口映射允许将某个容器端口映射到Docker主机端口上。对于配置中指定的Docker主机端口,任何发送到该端口的流量,都会被转发到容器。图中展示了具体流量动向。
2. Container#
指定新创建的容器和已经存在的一个容器共享一个 Network Namespace ,而不是和宿主机共享。新创建的容器不会创建自己的网卡,配置自己的 IP ,而是和一个指定的容器共享 IP 、端口范围等。同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的。两个容器的进程可以通过 lo 网卡设备通信。
# 参数
docker run --network container:<container_id> <image>
新的容器将共享指定容器的网络堆栈,包括 IP 地址、端口等。这种模式使得多个容器可以共享网络配置,但并没有独立的网络空间。
3. Host#
如果启动容器的时候使用 host 模式,那么这个容器将不会获得一个独立的 Network Namespace ,而是和宿主机共用一个 Network Namespace 。容器将不会虚拟出自己的网卡,配置自己的 IP 等,而是使用宿主机的 IP 和端口。但是,容器的其他方面,如文件系统、进程列表等还是和宿主机隔离的。
docker run --network host <image>

4.None#
none网络模式会为容器分配一个独立的网络命名空间,但该容器没有任何网络连接。- 工作原理:容器在
none网络模式下不会自动连接到任何网络,容器没有 IP 地址,也不能访问外部网络。你需要手动配置容器的网络连接(如使用docker exec进入容器并进行手动配置),或者通过手动创建虚拟网络设备来实现容器间的通信。 - 适用场景:适用于需要完全控制容器网络配置的场景,或者你希望容器完全没有网络访问权限时(例如,做一个完全隔离的安全容器)。

docker run --network none <image>
| 网络模式 | 描述 | 适用场景 |
|---|---|---|
| Bridge | 默认网络,容器连接到虚拟桥接网络 | 多个容器需要相互通信并且可以与宿主机或外部网络通信。 |
| Container | 容器共享另一个容器的网络堆栈 | 紧密集成的容器共享网络和端口,如运行多个服务的容器。 |
| Host | 容器与宿主机共享网络堆栈 | 网络性能要求高的应用,且不介意容器与宿主机缺乏隔离。 |
| None | 容器没有任何网络连接 | 完全隔离的容器或需要手动配置网络的特殊场景。 |

5. Overlay#
覆盖网络适用于多机环境。它允许单个网络包含多个主机,这样不同主机上的容器间就可以在链路层实现通信。覆盖网络是理想的容器间通信方式,支持完全容器化的应用,并且具备良好的伸缩性。这种网络类型特别适用于容器编排和集群环境,如Docker Swarm 或 Kubernetes
即使容器所在的Docker主机位于不同的底层网络上,该覆盖网络依然是相通的。本质上说,覆盖网络是创建于底层异构网络之上的一个新的二层容器网络。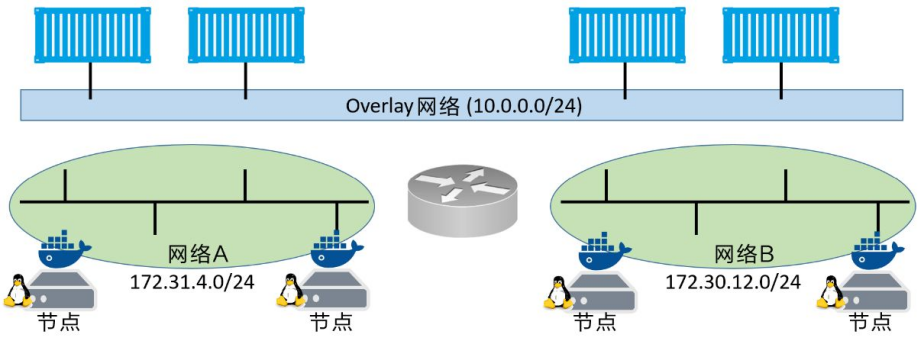
两个底层网络通过一个三层交换机连接,而基于这两个网络之上是一个覆盖网络。Docker主机通过两个底层网络相连,而容器则通过覆盖网络相连。对于同一覆盖网络中的容器来说,即使其各自所在的Docker主机接入的是不同的底层网络,也是互通的
原理:虚拟网络:Docker 创建一个虚拟网络,覆盖在多个物理主机之上。容器可以在这个虚拟网络中相互通信,就像它们在同一个局域网中一样。
**特点:**无需端口映射:与单机桥接网络不同,overlay 网络中的容器不需要将端口映射到宿主机上。容器可以直接通过 overlay 网络访问其他容器
覆盖网络的创建#
docker network create -d overlay net_name
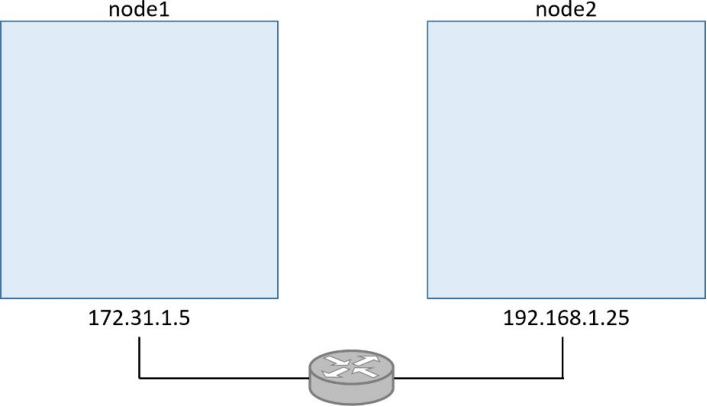
要完成下面的示例,需要两台Docker主机,并通过一个路由器上两个独立的二层网络连接在一起。如图所示,注意节点位于不同网络之上
Linux内核版本不能低于4.4(高版本更好),Windows需要Windows Server 2016版本,并且应安装最新的补丁
1.构建Swarm
首先需要将两台主机配置为包含两个节点的Swarm集群。接下来会在node1节点上运行docker swarm init 命令使其成为管理节点,然后在node2节点上运行docker swarm join 命令来使其成为工作节点。
如果读者需要在自己的环境中继续下面的示例,则需要先将环境中的IP地址、容器ID和Token等替换为正确的值。
在node1 节点上运行下面的命令。
$ docker swarm init \
------------------------------------------------------------
--advertise-addr=172.31.1.5 \--listen-addr=172.31.1.5:2377Swarm initialized: current node (1ex3...o3px) is now a manager.
在node2 上运行下面的命令。如果需要在Windows环境下生效,则需要修改Windows防火墙规则,打开2377/tcp 、7946/tcp 以及7946/udp 等几个端口。
$ docker swarm join \
--token SWMTKN-1-0hz2ec...2vye \172.31.1.5:2377This node joined a swarm as a worker.
2.创建新的覆盖网络
现在创建一个名为uber-net 的覆盖网络。
在node1 (管理节点)节点上运行下面的命令。
$ docker network create -d overlay uber-netc740ydi1lm89khn5kd52skrd9
------------------------------------------------------------
创建了一个崭新的覆盖网络,能连接Swarm集群内的所有主机,并且该网络还包括一个TLS加密的控制层!如果还想对数据层加密的话,只需在命令中增加-o encrypted 参数。
$ docker network ls
NETWORK ID NAME DRIVER SCOPEddac4ff813b7 bridge bridge ocal389a7e7e8607 docker_gwbridge bridge locala09f7e6b2ac6 host host localehw16ycy980s ingress overlay swarm2b26c11d3469 none null local**c740ydi1lm89** **uber-net** **overlay** **swarm**
如果在node2 节点上运行docker network ls 命令,就会发现无法看到uber-net 网络。这是因为只有当运行中的容器连接到覆盖网络的时候,该网络才变为可用状态。这种延迟生效策略通过减少网络梳理,提升了网络的扩展性。
3.将服务连接到覆盖网络
现在覆盖网络已经就绪,接下来新建一个Docker服务并连接到该网络。Docker服务会包含两个副本(容器),一个运行在node1 节点上,一个运行在node2 节点上。这样会自动将node2 节点接入uber-net 网络。
在node1节点上运行下面的命令。
------------------------------------------------------------
$ docker service create --name test \
--network uber-net \--replicas 2 \ubuntu sleep infinity
该命令创建了名为test 的新服务,
连接到了uber-net 这个覆盖网络,
基于指定的镜像创建了两个副本(容器)。
在两个示例中,均在容器中采用sleep命令来保持容器运行,并在休眠结束后退出该容器。
由于运行了两个副本(容器),而Swarm包含两个节点,因此每个节点上都会运行一个副本。
$ docker service ps test
------------------------------------------------------------
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE
77q...rkx test.1 ubuntu node1 Running Running
97v...pa5 test.2 ubuntu node2 Running Running
当Swarm在覆盖网络之上启动容器时,会自动将容器运行所在节点加入到网络当中。这意味着此时在node2 节点上就可以看到uber-net 网络了
4.测试覆盖网络
现在使用ping命令来测试覆盖网络。
在两个独立的网络中分别有一台Docker主机,并且两者都接入了同一个覆盖网络。目前在每个节点上都有一个容器接入了覆盖网络。测试一下两个容器之间是否可以ping通。
为了执行该测试,需要知道每个容器的IP地址(为了测试,暂时忽略相同覆盖网络上的容器可以通过名称来互相ping通的事实)。
运行docker network inspect 查看被分配给覆盖网络的Subnet 。
------------------------------------------------------------
$ docker network inspect uber-net
[{"Name": "uber-net","Id": "c740ydi1lm89khn5kd52skrd9","Scope": "swarm","Driver": "overlay","EnableIPv6": false,"IPAM": {"Driver": "default","Options": null,"Config": [{"Subnet": "10.0.0.0/24","Gateway": "10.0.0.1"}<Snip>
uber-net 的子网是10.0.0.0/24 。注意,这与两个节点的任意底层物理网络IP均不相符(172.31.1.0/24 和192.168.1.0/24 )。
在node1 和node2 节点上运行下面两条命令。这两条命令可以获取到容器ID和IP地址。
$ docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS
396c8b142a85 ubuntu:latest "sleep infinity" 2 hours ago Up 2 hrs
$ docker container inspect \
--format='{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}'\
396c8b142a85
10.0.0.3
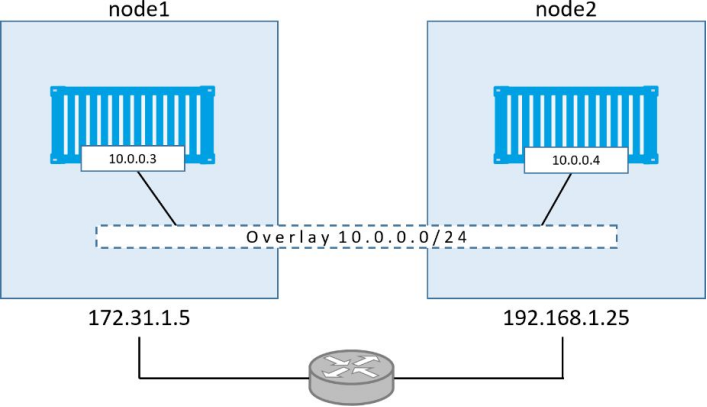
由图可知,一个二层覆盖网络横跨两台主机,并且每个容器在覆盖网络中都有自己的IP地址。
这意味着node1 节点上的容器可以通过node2 节点上容器的IP地址10.0.0.4 来ping通,该IP地址属于覆盖网络。尽管两个节点分属于不同的二层网络,还是可以直接ping通。验证如下:
$ docker container exec -it 396c8b142a85 bash
------------------------------------------------------------
root@396c8b142a85:/# apt-get update
root@396c8b142a85:/# apt-get install iputils-ping
Reading package lists... DoneBuilding dependency treeReading state information... DoneSetting up iputils-ping (3:20121221-5ubuntu2) ...Processing triggers for libc-bin (2.23-0ubuntu3) ...
root@396c8b142a85:/# ping 10.0.0.4
PING 10.0.0.4 (10.0.0.4) 56(84) bytes of data.64 bytes from 10.0.0.4: icmp_seq=1 ttl=64 time=1.06 ms64 bytes from 10.0.0.4: icmp_seq=2 ttl=64 time=1.07 ms64 bytes from 10.0.0.4: icmp_seq=3 ttl=64 time=1.03 ms64 bytes from 10.0.0.4: icmp_seq=4 ttl=64 time=1.26 ms^C
root@396c8b142a85:/#
还可以在容器内部跟踪ping命令的路由信息。路由信息只有一跳,证明容器间通信确实通过覆盖网络直连——无须关心底层网络,这太省心了。
$ root@396c8b142a85:/# traceroute 10.0.0.4traceroute to 10.0.0.4 (10.0.0.4), 30 hops max, 60 byte packets1 test-svc.2.97v...a5.uber-net (10.0.0.4) 1.110ms 1.034ms 1.073ms
到目前为止,已经通过单条命令创建了覆盖网络,并向该网络中接入了容器。这些容器分布在两个不同的主机上,两台主机分属于不同的二层网络。在找出两台容器的IP之后,验证了容器可以通过覆盖网络完成直连。
VXLAN#
Vxaln介绍#
Docker使用VXLAN隧道技术创建了虚拟二层覆盖网络
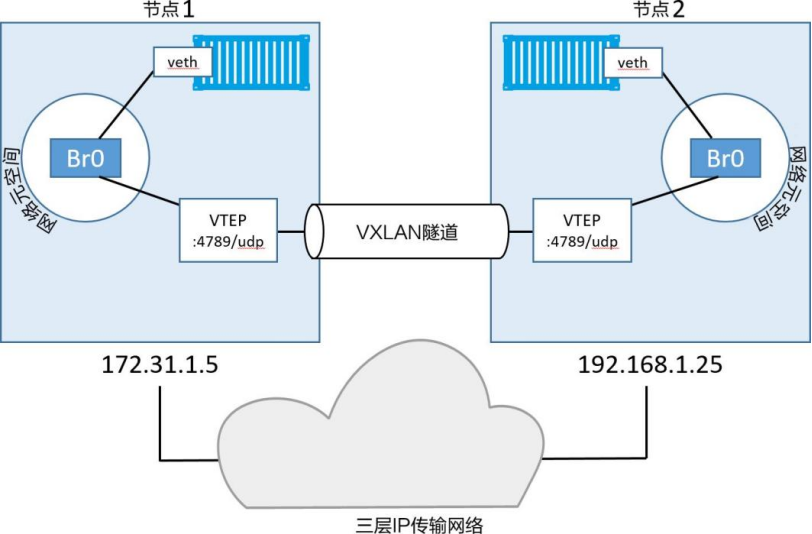
在VXLAN的设计中,允许用户基于已经存在的物理三层网络结构创建逻辑虚拟的二层网络。在前面的示例中创建了一个子网掩码为10.0.0.0/24的二层网络,该网络是基于一个三层IP网络实现的,三层IP网络由172.31.1.0/24和192.168.1.0/24这两个二层网络构成。具体如图所示
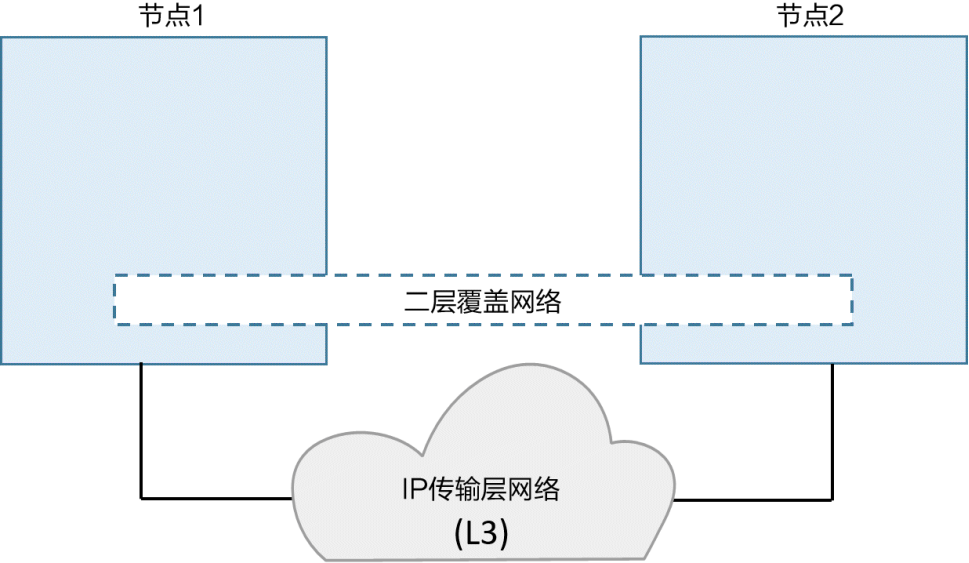
VXLAN的美妙之处在于它是一种封装技术,能使现存的路由器和网络架构看起来就像普通的IP/UDP包一样,并且处理起来毫无问题。
为了创建二层覆盖网络,VXLAN基于现有的三层IP网络创建了隧道。基础网络(Underlay Network)这个术语,它用于指代三层之下的基础部分
VXLAN隧道两端都是VXLAN隧道终端(VXLAN Tunnel Endpoint, VTEP)。VTEP完成了封装和解压的步骤,以及一些功能实现所必需的操作,如图所示。
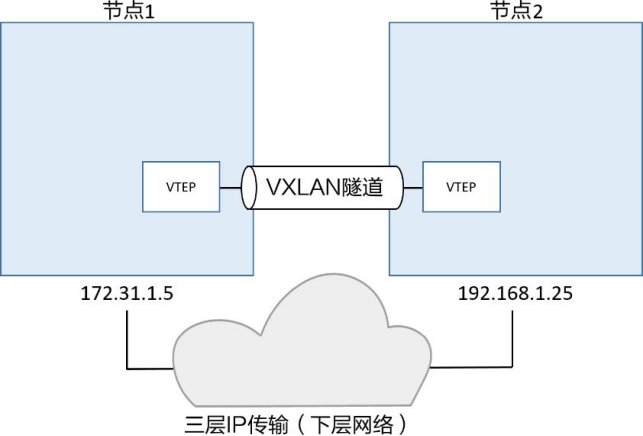
Vxlan在多主机容器通信的应用#
通过IP网络将两台主机连接起来。每个主机运行了一个容器,之后又为容器连接创建了一个VXLAN覆盖网络。
为了实现上述场景,在每台主机上都新建了一个Sandbox(网络命名空间)。正如前文所讲,Sandbox就像一个容器,但其中运行的不是应用,而是当前主机上独立的网络栈。
在Sandbox内部创建了一个名为Br0 的虚拟交换机(又称做虚拟网桥),每个容器都会有自己的虚拟以太网(veth)适配器,并接入本地Br0 虚拟交换机
同时Sandbox内部还创建了一个VTEP,其中一端接入到名为Br0 的虚拟交换机当中,另一端接入主机网络栈(VTEP)。
在主机网络栈中的终端从主机所连接的基础网络中获取到IP地址,并以UDP Socket的方式绑定到4789端口。
# 相关名词
1. Veth(Virtual Ethernet)是一种虚拟网络设备,通常用于在虚拟机或容器中创建虚拟的网络接口
2. VTEP(VXLAN Tunnel Endpoints) 是一种网络设备,用于在 VXLAN(Virtual Extensible Local Area Network)网络架构中创建和管理隧道。VXLAN 是一种网络虚拟化技术,通过封装以太网帧在 UDP 包中,允许跨越广域网(WAN)的网络流量传输。
3. VXLAN(Virtual Extensible Local Area Network,虚拟可扩展局域网)是一种网络虚拟化技术,它允许在物理网络之上创建多个虚拟网络。VXLAN:工作在网络层之上(OSI 模型的第三层或第四层)。VXLAN 通过在以太网帧外封装一个 UDP 包来实现网络虚拟化
容器通信过程#
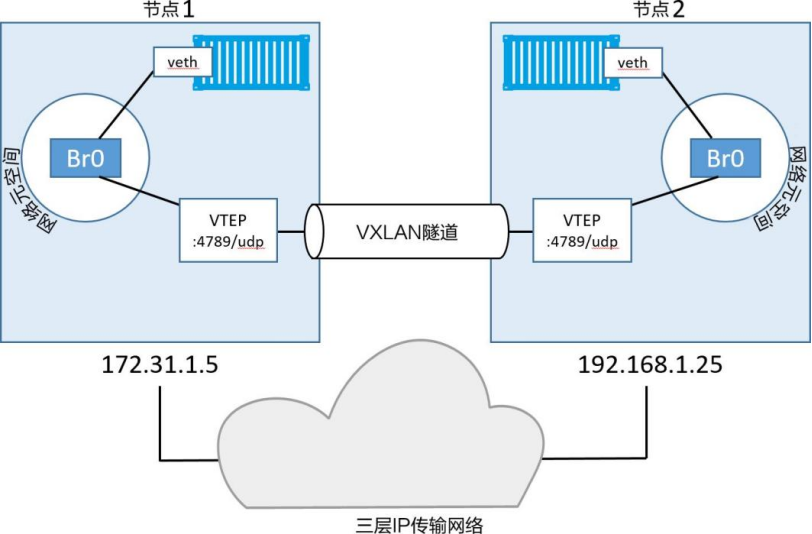
将node1上的容器称为C1 ,node2上的容器称为C2 ,如下图所示。假设C1 希望ping通C2
# 发送过程
(1)C1 发起ping请求,目标IP为C2 的地址10.0.0.4 。
(2)该请求的流量通过连接到Br0 虚拟交换机的veth接口发出。
(3)虚拟交换机并不知道将包发送到哪里,因为在虚拟交换机的MAC地址映射表(ARP映射表)中并没有与当前目的IP对应的MAC地址。所以虚拟交换机会将该包发送到其上的全部端口。
(4)连接到Br0 的VTEP接口知道如何转发这个数据帧,所以会将自己的MAC地址返回。这就是一个代理ARP响应,并且虚拟交换机Br0 根据返回结果学会了如何转发该包。
(5)接下来虚拟交换机会更新自己的ARP映射表,将10.0.0.4映射到本地VTEP的MAC地址上。
(6)现在Br0 交换机已经学会如何转发目标为C2 的流量,接下来所有发送到C2 的包都会被直接转发到VTEP接口。
(7)VTEP接口知道C2,是因为所有新启动的容器都会将自己的网络详情采用网络内置Gossip协议发送给相同Swarm集群内的其他节点。
# 接收过程
(1)交换机会将包转发到VTEP接口,VTEP完成数据帧的封装,这样就能在底层网络传输。具体来说,封装操作就是把VXLAN Header信息添加以太帧当中。
(2)VXLAN Header信息包含了VXLAN网络ID(VNID),其作用是记录VLAN到VXLAN的映射关系。每个VLAN都对应一个VNID,以便包可以在解析后被转发到正确的VLAN。
(3)封装的时候会将数据帧放到UDP包中,并设置UDP的目的IP字段为node2节点的VTEP的IP地址,同时设置UDP Socket端口为4789。这种封装方式保证了底层网络之间是透明的,也可以完成数据传输。
(4)当包到达node2之后,内核发现目的端口为UDP端口4789,同时还知道存在VTEP接口绑定到该Socket。所以内核将包发给VTEP,由VTEP读取VNID,解压包信息,并根据VNID发送到本地名为Br0 的连接到VLAN的交换机。在该交换机上,包被发送给容器C2
覆盖网络实现三层路由#
Docker支持使用同样的覆盖网络实现三层路由。例如,读者可以创建包含两个子网的覆盖网络,Docker会负责子网间的路由。创建的命令如下
docker network create --subnet=10.1.1.0/24 --subnet=11.1.1.0/24 -d overlayprod-net
该命令会在Sandbox中创建两个虚拟交换机,默认支持路由。
6. Macvlan#
能够将容器化应用连接到外部系统以及物理网络的能力是非常必要的。常见的例子是部分容器化的应用——应用中已容器化的部分需要与那些运行在物理网络和VLAN上的未容器化部分进行通信。
Docker内置的Macvlan 驱动(Windows上是Transparent )就是为此场景而生。通过为容器提供MAC和IP地址,让容器在物理网络上成为“一等公民”
Macvlan的优点是性能优异,因为无须端口映射或者额外桥接,可以直接通过主机接口(或者子接口)访问容器接口。但是,Macvlan的缺点是需要将主机网卡(NIC)设置为混杂模式(Promiscuous Mode) ,这在大部分公有云平台上是不允许的。所以Macvlan对于公司内部的数据中心网络来说很棒(假设公司网络组能接受NIC设置为混杂模式),但是Macvlan在公有云上并不可行
正常模式:在正常模式下,网络接口卡只接收目的地是它自身 MAC 地址的数据包,以及广播和多播的数据包。
混杂模式:当网络接口卡被设置为混杂模式时,它会接收所有经过的网络流量,包括那些不发送给它的数据包。这意味着NIC能够看到在同一网络段上的所有数据包,而不仅仅是专门发给它的
举例:
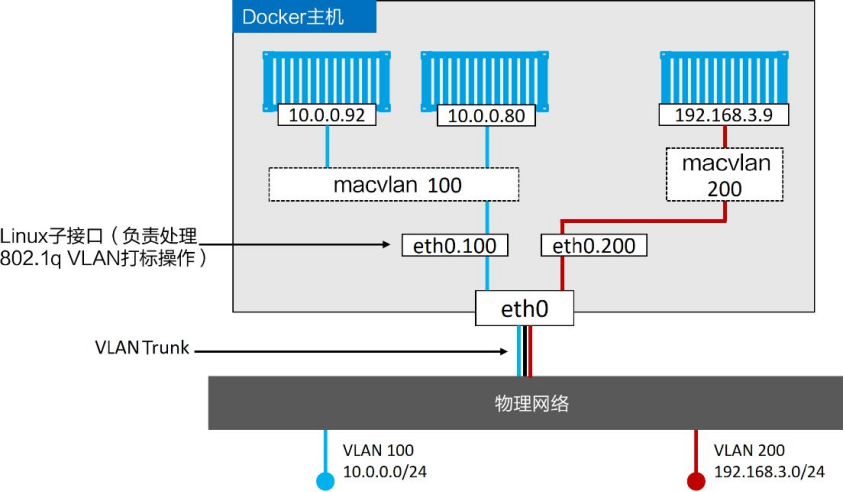
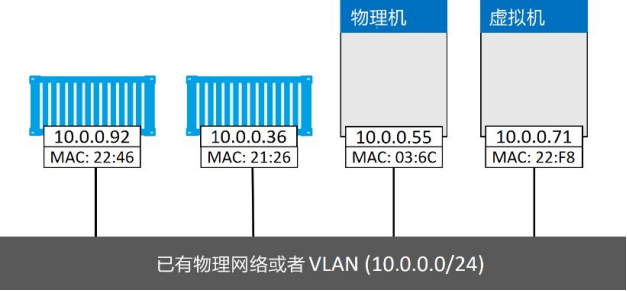
假设、有一个物理网络,其上配置了两个VLAN——VLAN 100:10.0.0.0/24和VLAN 200:192.168.3.0/24,如图

添加一个Docker主机并连接到该网络
有一个需求是将容器接入VLAN 100。为了实现该需求,首先使用Macvlan 驱动创建新的Docker网络。Macvlan 驱动在连接到目标网络前,需要设置几个参数。比如以下几点:子网信息、网关、可分配给容器的IP、主机使用的接口或者子接口
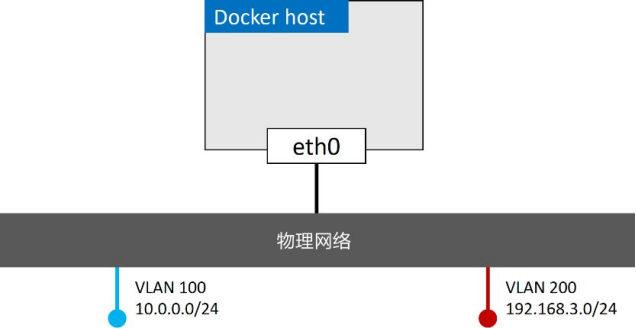
下面的命令会创建一个名为macvlan100 的Macvlan网络,该网络会连接到VLAN 100
$ docker network create -d macvlan \
--subnet=10.0.0.0/24 \
--ip-range=10.0.00/25 \
--gateway=10.0.0.1 \
-o parent=eth0.100 \
macvlan100
--ip-range=10.0.0.0/25:
这个参数用于限制容器可以获得的 IP 地址范围。在这个例子中,IP 地址范围是 10.0.0.0 到 10.0.0.127,提供 128 个地址供容器使用。这样可以控制容器的 IP 地址分配。
-o parent=eth0.100:
-o 是指定网络选项的参数。parent=eth0.100 指定了宿主机上使用的网络接口。这里 eth0.100 是一个子接口(通常在 VLAN 配置中使用),表示该 Macvlan 网络将基于这个接口进行数据传输。
该命令会创建macvlan100 网络以及eth0.100 子接口。当前配置如图
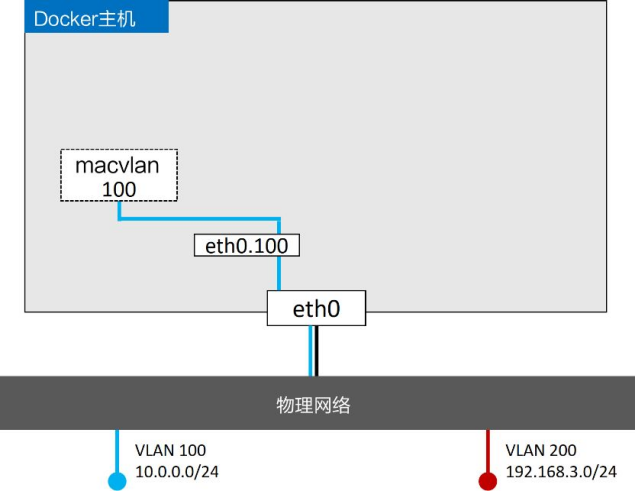
Macvlan采用标准Linux子接口,读者需要为其打上目标VLAN网络对应的ID。在本例中目标网络是VLAN 100,所以将子接口标记为 .100 (etho.100 )
macvlan100 网络已为容器准备就绪,执行以下命令将容器部署到该网络中
$ docker container run -d --name mactainer1 \
--network macvlan100 \
alpine sleep 1d
当前配置如图11.17所示。但是切记,下层网络(VLAN 100 )对Macvlan的魔法毫不知情,只能看到容器的MAC和IP地址。在该基础之上,mactainer1 容器可以ping通任何加入VLAN 100的系统,并进行通信
如果上述命令不能执行,可能是因为主机NIC不支持混杂模式。切记公有云平台不允许混杂模式。
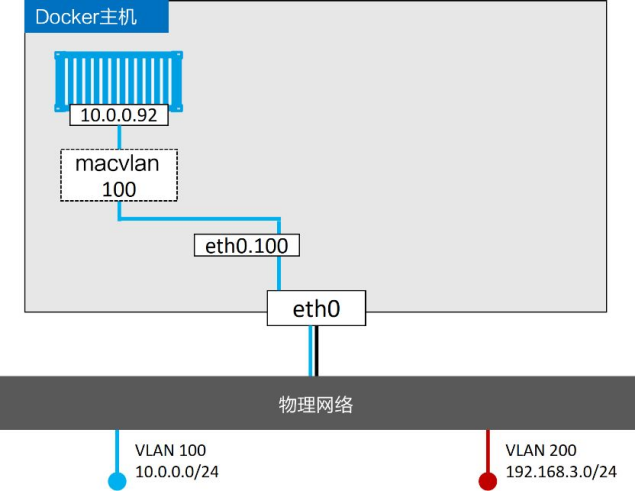
目前已经拥有了Macvlan网络,并有一台容器通过Macvlan接入了现有的VLAN当中。但是,这并不是结束。Docker Macvlan驱动基于稳定可靠的同名Linux内核驱动构建而成。因此,Macvlan也支持VLAN的Trunk功能。这意味着可以在相同的Docker主机上创建多个Macvlan网络,并且将容器按照图的方式连接起来